📝 Research :https://ojitha.blogspot.com.au for my lengthy articles.
Scala Notes

Explore fundamental Scala programming concepts including its functional and object-oriented nature, immutable variables , mutable variables, type inference, and basic syntax for defining functions and classes. This guide introduces key Scala features for developers familiar with other programming languages looking to understand its core principles and get started with Scala development. Discover the power and expressiveness of Scala through this concise overview of its building blocks.
Scala Collections
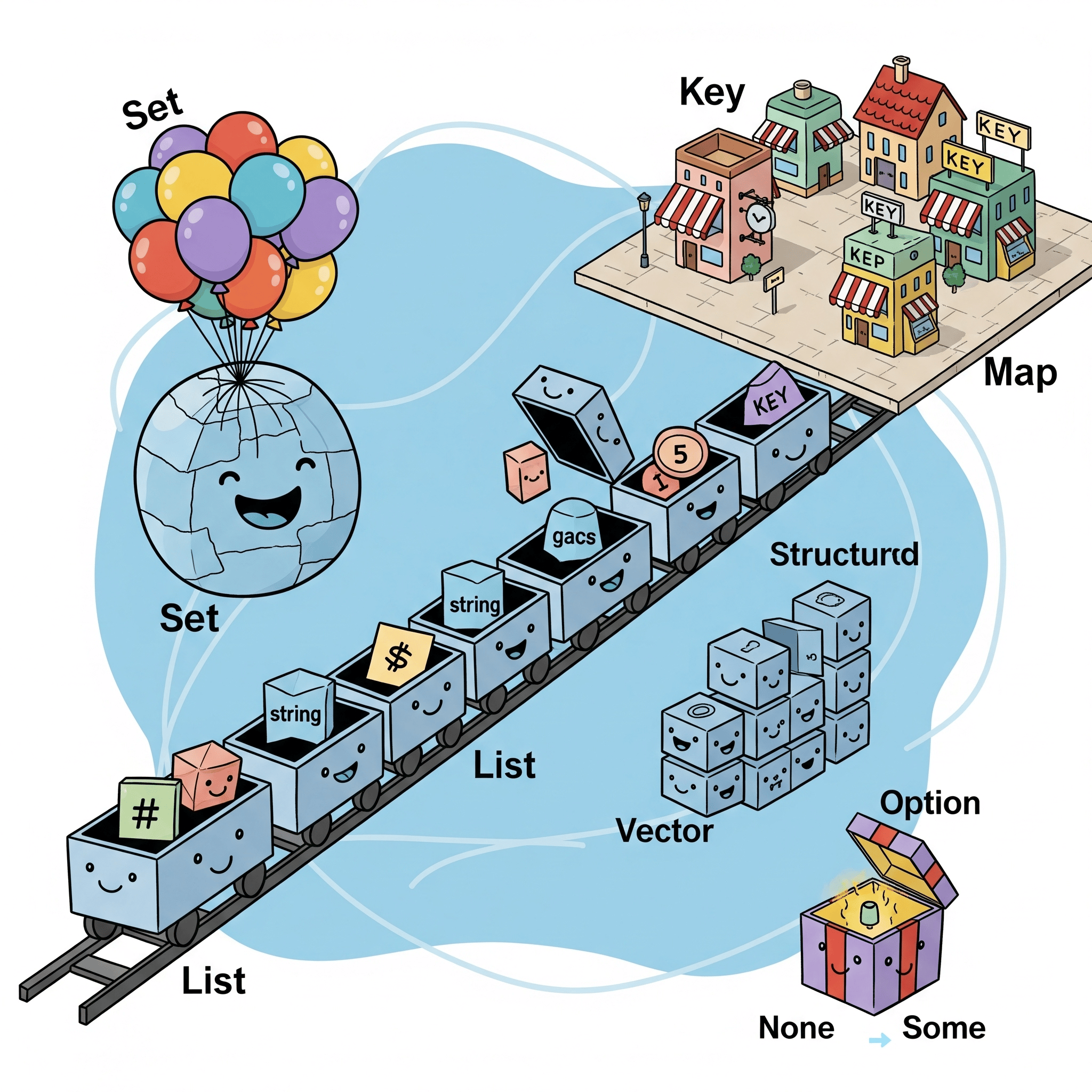
Explores the powerful Scala Collections library, detailing immutable and mutable collection types like Lists, Sets, and Maps, along with their common operations for efficient data manipulation. Understand the benefits of immutability and the flexibility of mutable collections in Scala for building robust applications. This guide highlights essential tools for any Scala developer working with structured data.
LLM Fine Tuning on AWS SageMaker
This comprehensive guide explores fine-tuning Large Language Models (LLMs) on AWS SageMaker, covering essential concepts from basic language model architecture to practical deployment. Learn about transformer-based models, self-attention mechanisms, and positional encoding that enable parallel processing of sequential data. Discover Parameter-Efficient Fine-Tuning (PEFT) techniques like LoRA that reduce trainable parameters by up to 10,000 times while maintaining performance. The tutorial demonstrates hands-on implementation using Databricks Dolly-v2-3b model, including dataset preparation, tokenization, and training configuration. Explore prompt engineering strategies including zero-shot, few-shot, and chain-of-thought approaches for optimal model outputs. Master n-gram tokenization principles underlying modern BPE and WordPiece methods. Follow step-by-step deployment instructions using SageMaker’s DJL framework, from model artifact creation to inference endpoint testing. Perfect for AI practitioners seeking cost-effective, domain-specific LLM customization on AWS infrastructure.
Azure DevOps pipeline to deploy Elasticsearch

This guide provides a comprehensive walkthrough for deploying an Elasticsearch application on an Azure Virtual Machine using an automated Azure DevOps pipeline. The process is broken down into four main parts: Azure VM Setup, Azure DevOps Pipeline Setup, Troubleshooting and Optimisation, and Security Recommendations.
UV is better than Pyenv for Python

UV is an excellent alternative to Pyenv, though they serve slightly different purposes. I have been using pyenv for more than 10 years. Is this the time for the alternative? It is important to note that UV doesn't support Python 2.*.