RegEx on MacOS

As I understood, RegExs are very useful for general work. Most of the following regular expressions (RegEx)s can be run on the macOS terminal, where you can get the great value of command line tools that have no value without RegExs (`grep`, `sed` and so on). In addition, I've used some popular tools to explain complex operations later in the document, which have been referenced under the footnotes.
- macOS grep or ggrep
- Find a text in a file
- Find in the folder
- Character Class
- Quantifiers
- Capture
- Lookarounds
- VSCode
- Stream editor
- Merge multiple lines to group of lines
macOS grep or ggrep
For the macOS, the default grep (FreeBSD version) is minimal. Using the macOS standard grep command, you cannot run all the bash commands expressed in this blog post. Therefore install the grep from the homebrew:
brew install grep
and use the command ggrep instead of grep. For the help
ggrep --help
NOTE: The improved grep is ggrep.
For testing purposes, download the texts of Shakespeare1 as a zip file after you extract the zip file.
Find a text in a file
To find the word in the TXT file:
egrep --color the hamlet_TXT_FolgerShakespeare.txt
This will show you something similar to the following output.

You can see the the is highlighted.
Find in the folder
Locate the file in the file system where every file shows the lines that contain text henry.
find . -exec egrep -H 'Henry IV' {} \; 2>/dev/null
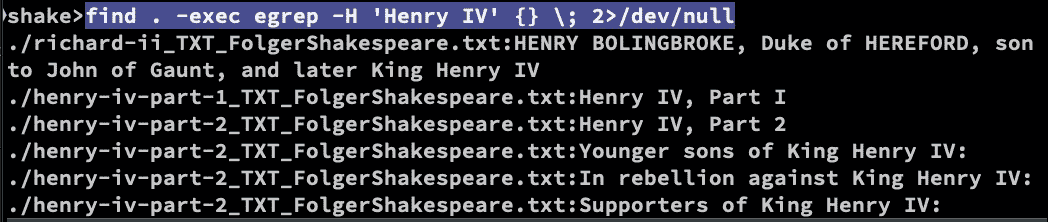
For example, case-sensitive match:
egrep --color 'the|is' hamlet_TXT_FolgerShakespeare.txt
For case insensitive matches, use the -i option.
egrep --color -i 'england' hamlet_TXT_FolgerShakespeare.txt

To implement the Enhanced Regular Expressions (ERE) dialect, use grep -E(grep -P say PCRE, for MacOS use the perl in the terminal), and egrep is the shortened form of that.
If you want a collection of text to match, you can use either alternation | or an external text file with the words.
echo 'england' >> search_keywords.txt
echo 'ambassadors' >> search_keywords.txt
echo 'gives' >> search_keywords.txt
Search command is
egrep --color -f search_keywords.txt hamlet_TXT_FolgerShakespeare.txt
To show the lines do not match (negative of the above), use v option:
egrep --color -v -i -f search_keywords.txt hamlet_TXT_FolgerShakespeare.txt
Character Class
You can create complex search key expressions using a class of characters. To create a character class, use the [] in the search. For example
egrep --color -i '[abc]' hamlet_TXT_FolgerShakespeare.txt
The complement of the above is [^abc].

For example:
Generic Character classes
| Generic | Class |
|---|---|
\d |
[0-9] |
| \D | [^0-9] |
\w |
[a-zA-Z0-9] |
\W |
[^a-zA-Z0-9] |
\s |
[\t\n\r\f] |
\S |
[^\t\n\r\f] |
For example
echo 'Hello Ojitha 1234' | grep --color -i '\D'

Only the words are selected.

Posix Character Classes
This has been created to simplify the character classes. The syntax is [[:CLASS:]]. Use the ^ as the complement [[:^CLASS:]].
Only Perl regex supports the following classes.
Use
Perlin the macOS terminal
| Posix | Characte Class | Description |
|---|---|---|
alnum |
[a-zA-Z0-9] | letters and digits |
word |
[a-zA-Z0-9] | word characters |
alpha |
[a-zA-Z] | Letters |
digit |
[0-9] | Digits |
lower |
[a-z] | lower case letters |
upper |
[A-Z] | upper case letters |
space |
[\t\n\f\r] | White space |
grep --color -E '[[:upper:]]' hamlet_TXT_FolgerShakespeare.txt
Or
perl -ne 'print if /[[:^word:]]/' hamlet_TXT_FolgerShakespeare.txt
Or
ggrep --color -P '[[:upper:]]' hamlet_TXT_FolgerShakespeare.txt
another example to search 12 and non other digits:

Quantifiers
In the regex expression, we want to quantify how many characters we want to match, for example.
| Quantifier | Description |
|---|---|
? |
0 or 1 |
* |
0 or more |
+ |
1 or more |
{n} |
n |
{n,} |
match n or more |
{n,m} |
match n thorugh m |
For example
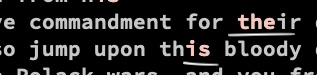
echo 'my 20 birtday party @ bay' |egrep --color '\d{2}\s\w{3}'
can be visualized2 as:
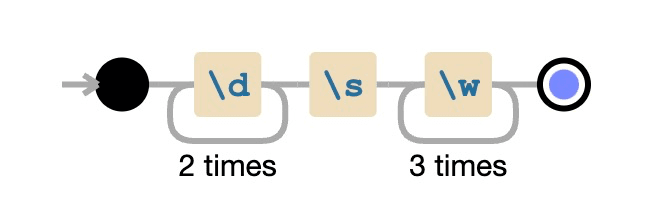
The output of the above regex is

In the Perl regex
echo 'my 20 Birtday party @ Bay' |grep --color -E '[[:upper:]]{1}'
output is

See the following example:

Quantifiers are greedy, the consume as much as they can.
Inline Modifiers
| Modifier | Description |
|---|---|
(?x) |
Embed whitespace |
(?i) |
Case insensitive match |
(?s) |
Single line mode |
(?m) |
Multi line mode, here \A start if the string and \Z end of the string. |
For example, although I specify the Posix class lower for lower letters, when you specify modifier (?xi), it shows all the words ignoring the Upper case letters.
echo 'my 20 Birtday party @ BAY' |ggrep --color -P '(?xi) [[:lower:]]'

Example use of multi-lines, starting (^) with Hello:
echo 'Hello
Ojitha
How are you' | ggrep --color -Pz '(?xm) ^Hello .* '
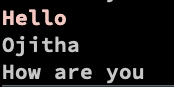
In the above bash command, -z option allows the input data to be a sequence of lines.
See the modification above for single line modifier:
echo 'Hello
Ojitha
How are you' | ggrep --color -Pz '(?xs) ^Hello .* '
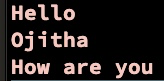
All the lines are selected because \n new line has been tread as another character in the single line(s) mode.
example of embedding white space

In the above regex the whitespace to search is given as \x20.

In the above regex, the new line is treated as \n because s treated the two lines as an one line.
if you use m instad of s:
Bounding
Bonding regex does not match characters, but they specify where in the string the regex is to be matched.
| Bounding | Meaning |
|---|---|
^ |
Beginning |
$ |
End of the string or before \n |
\A |
begining of string |
\Z |
end of string |
\b |
begining or end of a word |
\B |
complement of begining or end of a word |
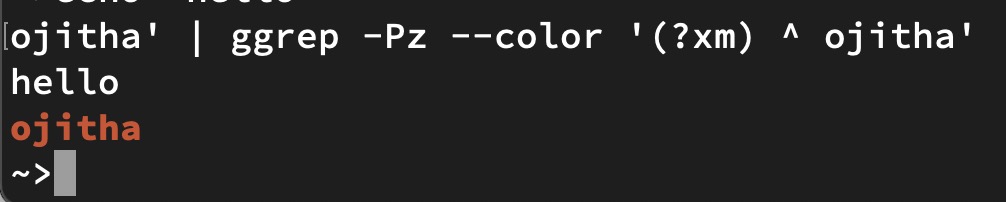
echo "the pen is my brother's" | ggrep -P --color '\bthe'

As shown above, brother’s is not selected because the word the is not the beginning of that word according to the bounding \b.
But, if you use bounding \B:
echo "the pen is my brother's" | ggrep -P --color '\Bthe'

alternation
Either match this or that: This has already been introduced in the beginning.
echo 'one and two are numbers' > test.txt
perl -pe 's/one|two/digit/' test.txt
digit and two are numbers
You can use alternation with bounds as follows:
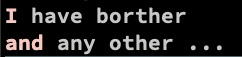
echo 'I have borther
but I have no sisters
and any other ...' | ggrep -P --color '^I|the'
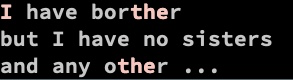
If you use in the group
echo 'I have borther
but I have no sisters
and any other ...' | ggrep -P --color '^(I|and)'
Lazy Quantifiers
Not going to consume greedy but minimally.
| Quntifier | Description |
|---|---|
*? |
zero or more minimal |
+? |
one or more minimal |
?? |
zero or one minimal |
{n}? |
n times minimal (n is numeric) |
{n,}? |
n times or more minimal (n is numeric) |
{n,m}? |
n through m minimal (n is numeric) |
As shown in the following screenshot, the first regex greedly consume and match the first letter a to last letter t. In the second regex, it matches the first and up to the closest letter t.

In the first grep command there is only one mactch. In the second, there are two maches: ‘azy is import’ and ‘ant’.
For example see the difference in the outputs when you apply lazy quantifier:

another example:

Possessive Quantifier
Possessive quantifiers are like normally greedy quantifiers, the important difference is that the possessive quantifiers do not backtrack (go back) unlike greedy quantifiers.
| Quantifier | Description |
|---|---|
*+ |
zero or more possessive |
++ |
one or more possessive |
| ?+ | zero or one possessive |
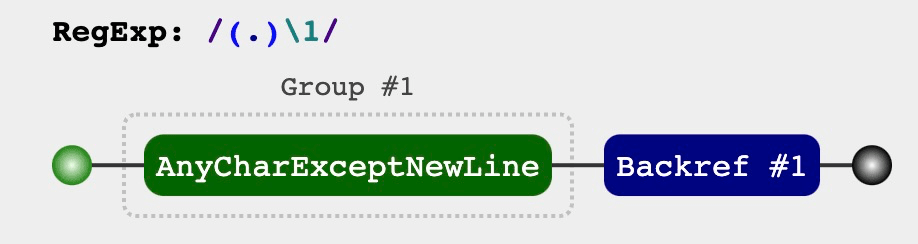
Capture
You can create capture groups using () as follows:
(.+)\.(png|gif)
The graphical representation3 is

The target string match as follows:

For non-capture groups, use the ?: as follows:
(.+)\.(?:png|gif)
The above regex matched the string but hasn’t captured the second group


you can reference the captured group later in the expression by the positional value
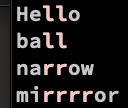
echo 'Hello
ball
narrow
mirrrror' | ggrep -P --color '(.)\1'
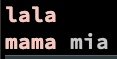
and visualisation4
echo 'Hello
memo
mississippi
rivier
lala
mama mia' | ggrep -P --color '(.)(.)\1\2'
This is same as above
echo 'Hello
memo
mississippi
rivier
lala
mama mia' | ggrep -P --color '(..)\1'
notice (..)\1.
Word followed the same word:
echo ' the song
I like ba baba black ship
wonder why' | ggrep -P --color '\b(\w+)\s\1'

Good practical example is HTML tag matching such as <(\w+)>.*?<\/\1> as shown in the visualisation:

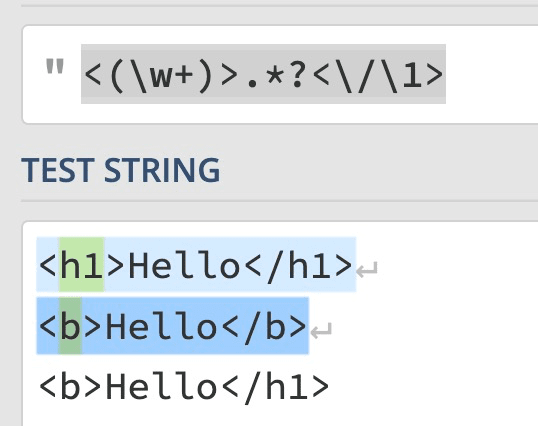
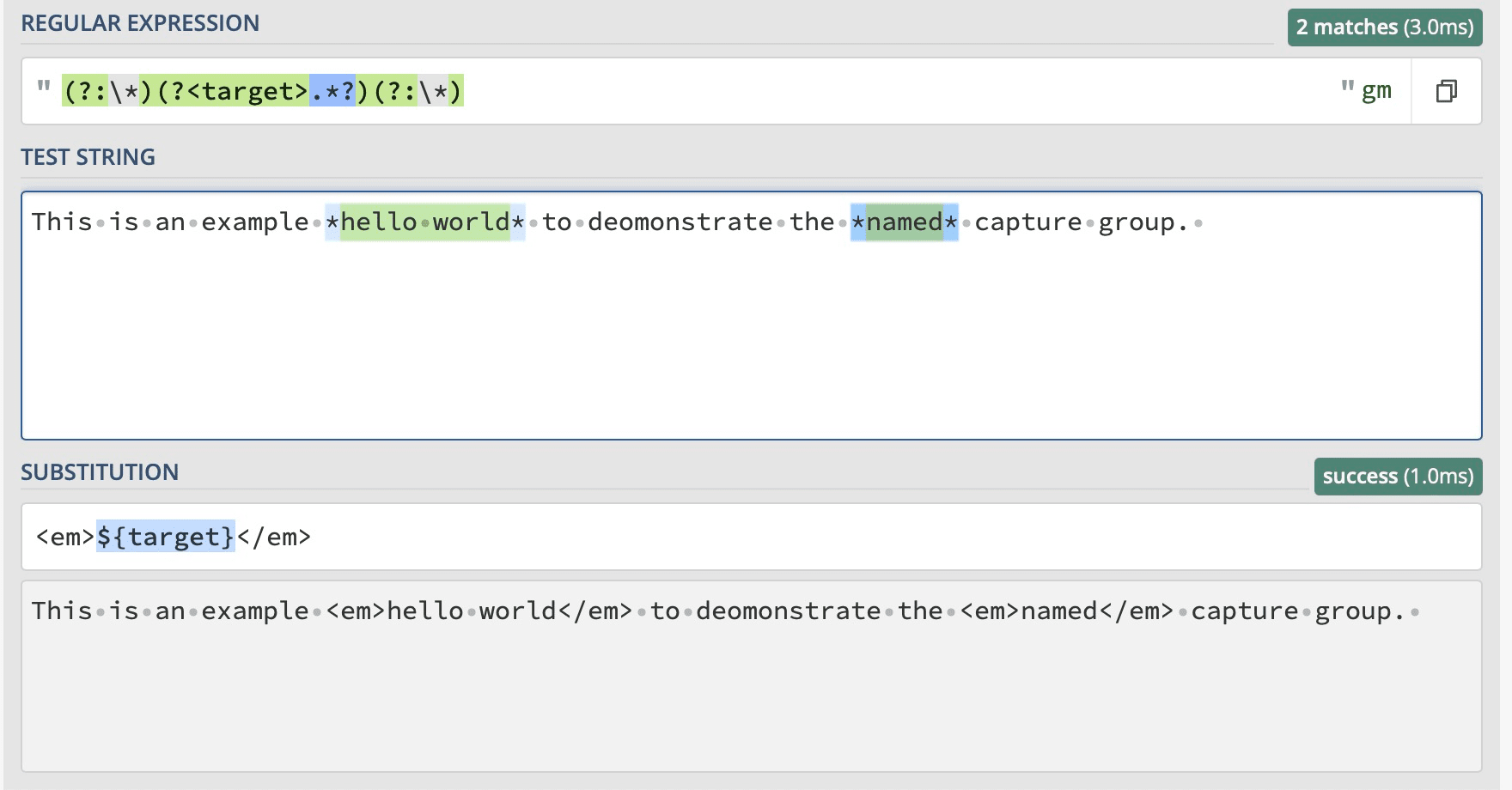
You can name the capture group as follows. In the editor5, you can substitute the HTML em tag in markdown bold text. More similar to boundary tokens.
Using Sed
sed -E 's/([a-z]*) (\d*)/text: \1, digits: \2/'
text: hello, digits: 123
For example, non capture using perl:

Lookarounds
Lookarounds are regex expression conditions that are not captured as a part of the match.
| Postive | Negative | |
|---|---|---|
| Lookahead | T (?=c): Capture T which statisfy the condition c after it. |
Negation of T (?!c) |
| Lookbehind | (?<=c) T: Capture T which satisfy the condtion c before it. |
Negation of(?<!c) T |
Examples:
| Postive Lookahead |  |
 |
| Negative Lookahead |  |
 |
| Positive lookbehind |  |
|
| Negative Lookbehind |  |
NOTE: Python support only fixed-width lookarounds. Indermine quantifiers such as
*,?,+are not allowed.
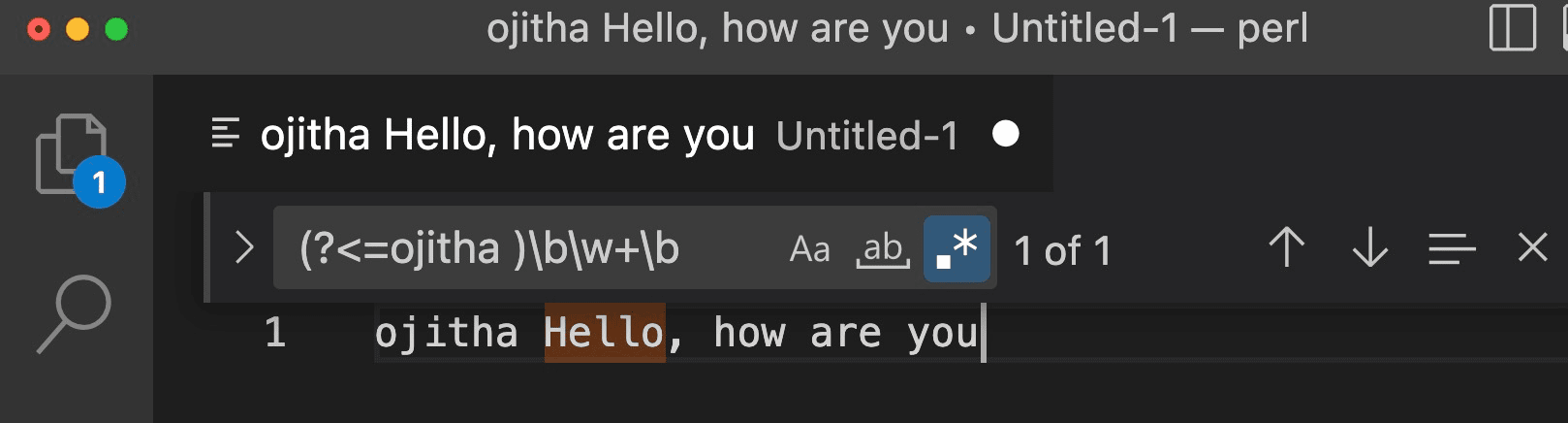
Example of Postive Lookahead where I want to remote date_parse and date_format function from the following line:
GROUP BY "date_trunc"('day', "date_parse"("date_format"(convert_timezone('Australia/Sydney', table-a.field-x), '%d/%m/%Y %H:%i:%s'), '%d/%m/%Y %H:%i:%s'))
The regular expression to find is "date_parse"\(.*(convert_timezone.*?\)).*(?=\)) and the replacement in VSCode, is $1. The Postive Lookahead has been used to avoid the selection of last ).
VSCode
You can use VSCode to capture the CSV column and modify it. For example,
| Before | After |
|---|---|
 |
 |
Look
VSCode support the lookarounds as well.
In the following example, I’ve used the Glasp: PDF & Web Highlighter for Researchers & Learners to get the following transcript for the https://www.youtube.com/watch?v=ZrSc_P6baQI&list=PLdQruVCKu10kK6ZD68hOdynzP_TyY4KV- youtube video.
(00:04) why do dictionaries ...
(00:35) exception it gives you a...
(01:04) characters and we look up ...
to update the above to have timeline markdown link, use the following regex
search: \((\d{2}):(\d{2})
Replace: [$1:$2](https://www.youtube.com/watch?v=ZrSc_P6baQI&list=PLdQruVCKu10kK6ZD68hOdynzP_TyY4KV-&t=$1m$2s
The output will be something similar to
[00:04](https://www.youtube.com/watch?v=ZrSc_P6baQI&list=PLdQruVCKu10kK6ZD68hOdynzP_TyY4KV-&t=00m04s) why do dictionaries ...
[00:35](https://www.youtube.com/watch?v=ZrSc_P6baQI&list=PLdQruVCKu10kK6ZD68hOdynzP_TyY4KV-&t=00m35s) exception it gives you a...
[01:04](https://www.youtube.com/watch?v=ZrSc_P6baQI&list=PLdQruVCKu10kK6ZD68hOdynzP_TyY4KV-&t=01m04s) characters and we look up ...
Stream editor
By default, sed uses the BRE dialect. The -E option uses ERE. The sed command can modify a file inline using the -i option.
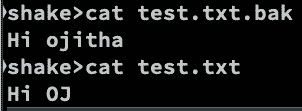
touch test.txt
echo 'Hi ojitha' > test.txt
sed -i '.bak' 's/ojitha/OJ/' test.txt
Text mactches using &:
echo 'Hello ojitha' | sed 's/oj.*/(&)/g'
Hello (ojitha)
Merge multiple lines to group of lines
For example you want to couple two lines to one line int he following text:
11111,
22222,
33333,
44444,
55555,
66666,
77777,
88888,
99999,
You have to follow 4 steps in the visual studio code
- search regex:
(^(\d+,\n){2})and replace regex:--$1--and the result is--11111, 22222, ----33333, 44444, ----55555, 66666, ----77777, 88888, --99999,In the above code, 2 lines are selected to compose as an one line.
- search regx:
\nand replace regex: empty and the result is--11111,22222,----33333,44444,----55555,66666,----77777,88888,--99999, - search regex:
----and replace regex:\nand the retults is--11111,22222, 33333,44444, 55555,66666, 77777,88888,--99999, - search :
--and replace: empty and the result is11111,22222, 33333,44444, 55555,66666, 77777,88888,99999,
-
Download The Folger Shakespeare – Complete Set ↩