Kafka PySpark streaming example
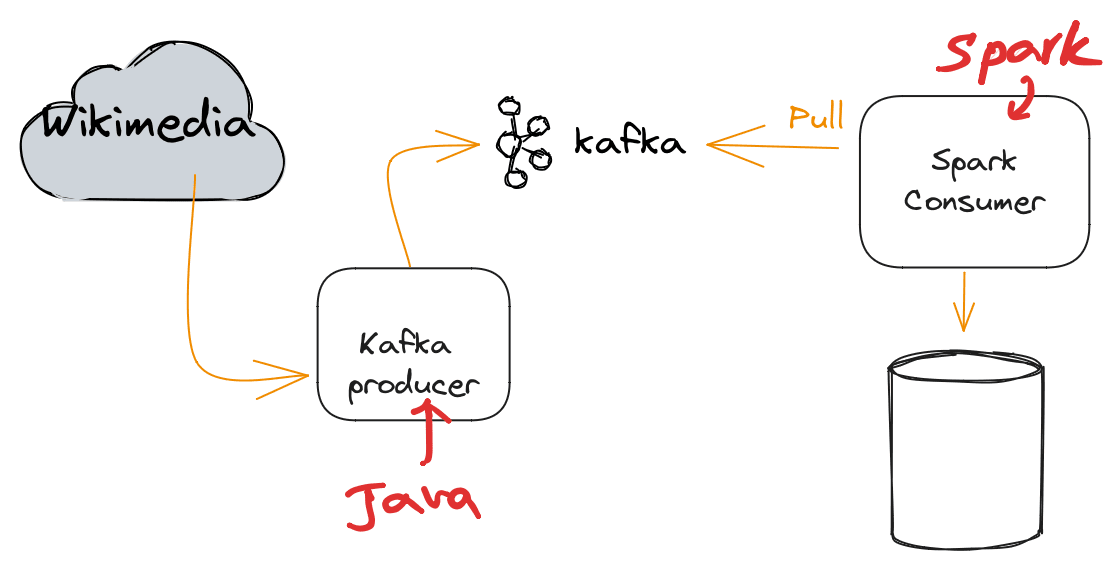
The diagram shows that the Kafka producer reads from Wikimedia and writes to the Kafka topic. Then Kafka Spark consumer pulls the data from the Kafka topic and writes the steam batches to disk.
I previously explained Spark Streaming Basics1 and Spark Kafka Docker Configuration2.
Install
Here the architecture of the streaming architecture following in this post:
How to start Zookeeper
zookeeper-server-start.sh ~/dev/kafka_2.13-3.1.0/config/zookeeper.properties
Start Kafka
kafka-server-start.sh ~/dev/kafka_2.13-3.1.0/config/server.properties
To list the Kafka topics:
kafka-topics.sh --list --bootstrap-server 127.0.0.1:9092
To create a topic
kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --topic <topic-name>
You can install Apache Spark 3.0.0 using SDKMAN on MacOS.
Kafka Producer
Kafka consumer3 reads the clickstream from https://stream.wikimedia.org/v2/stream/recentchange and writes to the Kafka topic via port 9092.
package au.com.blogspot.ojitha.kafka.examples.wikimedia;
import com.launchdarkly.eventsource.EventHandler;
import com.launchdarkly.eventsource.EventSource;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import java.net.URI;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
class WikimediaChangesProducer {
public static void main(String[] args) throws InterruptedException {
// create Producer Properties
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//set high throuput producer configs
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "20");
properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, Integer.toString(32 * 1024));
properties.setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
// create the Producer
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
String topic = <topic-name>;
EventHandler eventHandler = new WikimediaChangeHandler(producer, topic);
String url = "https://stream.wikimedia.org/v2/stream/recentchange";
EventSource.Builder builder = new EventSource.Builder(eventHandler, URI.create(url));
EventSource eventSource = builder.build();
// start the producer in another thread
eventSource.start();
// we produce for 10 minutes and block the program until then
TimeUnit.MINUTES.sleep(10);
The gradle file:
plugins {
id 'java'
}
group 'au.com.blogspot.ojitha.kafka.examples'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
// https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients
implementation 'org.apache.kafka:kafka-clients:3.3.1'
// https://mvnrepository.com/artifact/org.slf4j/slf4j-api
implementation 'org.slf4j:slf4j-api:2.0.5'
// https://mvnrepository.com/artifact/org.slf4j/slf4j-simple
implementation 'org.slf4j:slf4j-simple:2.0.5'
// https://mvnrepository.com/artifact/com.squareup.okhttp3/okhttp
implementation 'com.squareup.okhttp3:okhttp:4.9.3'
// https://mvnrepository.com/artifact/com.launchdarkly/okhttp-eventsource
implementation 'com.launchdarkly:okhttp-eventsource:2.5.0'
}
Kafka Spark Consumer
Here the simple Kafka Spark consumer reads from the Kafa topic and writes the stream to disk. This consumer is written in PySpark for simplicity.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Kafka Stream Test") \
.config ("spark.streaming.stopGracefullyOnShutdown", "true") \
.config ("spark.sql.shuffle.partitions",3) \
.getOrCreate()
line_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "<topic-name>") \
.option("startingOffsets", "earliest") \
.load()
df = line_df.selectExpr("CAST(value AS STRING)")
outDF = df.writeStream \
.format("text") \
.option("path","/Users/<user-name>/.../container/test/mytest.txt") \
.outputMode("append") \
.option("checkpointLocation", "chk-point-dir-1") \
.start()
outDF.awaitTermination()
Suffle partitions were reduced to 3 in line# 5, and configured the graceful shutdown when you interrupt the process.
Submit the Job
You need the package org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.0 to submit the job. Therefore, download the spark-sql-kafka-0-10_2.12-3.0.0.jar:
wget https://repo1.maven.org/maven2/org/apache/spark/spark-sql-kafka-0-10_2.12/3.0.0/spark-sql-kafka-0-10_2.12-3.0.0.jar
Submit the job as follows:
spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.0 <file-name>.py
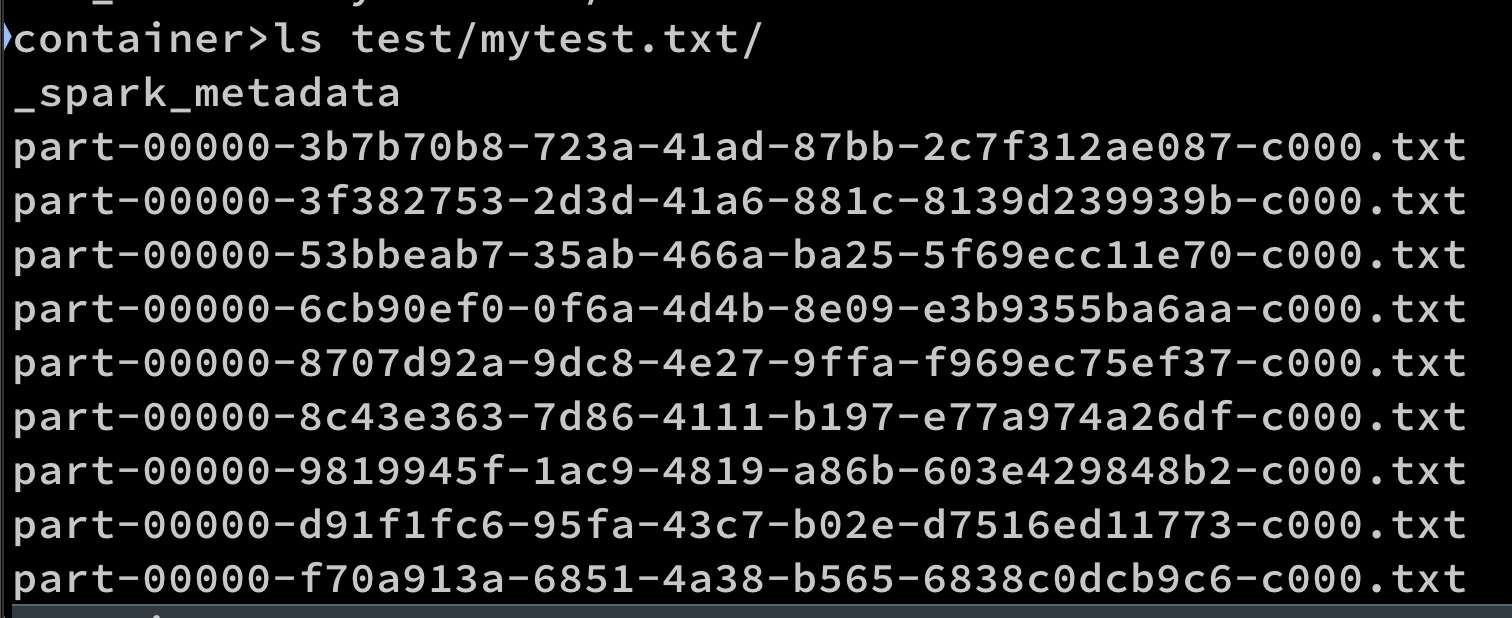
You can check the output as above.
VSCode Development Environment
The above spark submission does not help to debug the code. Therefore, you can set up the VSCode environment. I use the Pyenv package for Python environments, allowing me to install any Python version and create a virtual environment from any of those versions. You can find more information on setting up the Pyenv from my blog post, Python workflow4.
First, create your virtual environment after installing Python version 3.9.2.
pyenv virtualenv 3.9.2 spark
Activate the virtual environment:
pyenv activate spark
I am using Apache Spark 3.0.0. Therefore, install the same PySpark version in the virtual environment as well:
pip3 install pyspark==3.0.0
If the PySpark version is incompatible with the Spark version, you will get a Py4J error.
You need environment variables SPARK_HOME and PYTHONPATH to run or debug the Python from the VSCode. Therefore, create a launch configuration. Here is my launch.json file:
{
"version": "0.2.0",
"configurations": [
{
... other configurations
},
{
"name": "Python: Spark",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": false,
"env": {
"PYSPARK_PYTHON": "/usr/local/bin/python3.9",
"SPARK_HOME": "/Users/<username>/.sdkman/candidates/spark/current",
"PYTHONPATH": "/Users/<username>/.sdkman/candidates/spark/current/python/lib/py4j-0.10.9-src.zip",
"PATH": "${SPARK_HOME}/bin;${PATH}",
}
}
]
}
You must find the correct
py4j-<version>--src.zipfile name by navigating to theSPARK_HOME/python/lib.
Use the above launch configuration to run the Python script.
You have to add the org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.0 package to the spark-defaults.conf. For example, rename the spark-defaults.conf.template to spark-defaults.conf.
mv /Users/<username>/.sdkman/candidates/spark/current/conf/spark-defaults.conf.template /Users/<username>/.sdkman/candidates/spark/current/conf/spark-defaults.conf
Add the package to the spark-defaults.conf file, as shown in the second line:
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.jars.packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.0
If the configuration is not found, the error is
Failed to find data source: kafka.will be generated. Alternatively, You can use.config('spark.jars.packages','org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.0)in the spark configuration, but note recommended under the best practises.
This package is necessary to connect with Kafka in the runtime.
-
Apache Kafka Series - Learn Apache Kafka for Beginners v3, Stéphane Maarek ↩