Elastic Search Introduction
This post is on ElasticSearch 8 and the Elastic Stack1.
Install
In this post, I have used Docker to install ElasticSearch. This has minimised the effort of getting started. Here the docker-compose.yml file taken from a official article2:
version: "3.8"
volumes:
certs:
driver: local
esdata01:
driver: local
kibanadata:
driver: local
networks:
default:
name: elastic
external: false
services:
setup:
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
volumes:
- certs:/usr/share/elasticsearch/config/certs
user: "0"
command: >
bash -c '
if [ x${ELASTIC_PASSWORD} == x ]; then
echo "Set the ELASTIC_PASSWORD environment variable in the .env file";
exit 1;
elif [ x${KIBANA_PASSWORD} == x ]; then
echo "Set the KIBANA_PASSWORD environment variable in the .env file";
exit 1;
fi;
if [ ! -f config/certs/ca.zip ]; then
echo "Creating CA";
bin/elasticsearch-certutil ca --silent --pem -out config/certs/ca.zip;
unzip config/certs/ca.zip -d config/certs;
fi;
if [ ! -f config/certs/certs.zip ]; then
echo "Creating certs";
echo -ne \
"instances:\n"\
" - name: es01\n"\
" dns:\n"\
" - es01\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
" - name: kibana\n"\
" dns:\n"\
" - kibana\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
> config/certs/instances.yml;
bin/elasticsearch-certutil cert --silent --pem -out config/certs/certs.zip --in config/certs/instances.yml --ca-cert config/certs/ca/ca.crt --ca-key config/certs/ca/ca.key;
unzip config/certs/certs.zip -d config/certs;
fi;
echo "Setting file permissions"
chown -R root:root config/certs;
find . -type d -exec chmod 750 \{\} \;;
find . -type f -exec chmod 640 \{\} \;;
echo "Waiting for Elasticsearch availability";
until curl -s --cacert config/certs/ca/ca.crt https://es01:9200 | grep -q "missing authentication credentials"; do sleep 30; done;
echo "Setting kibana_system password";
until curl -s -X POST --cacert config/certs/ca/ca.crt -u "elastic:${ELASTIC_PASSWORD}" -H "Content-Type: application/json" https://es01:9200/_security/user/kibana_system/_password -d "{\"password\":\"${KIBANA_PASSWORD}\"}" | grep -q "^{}"; do sleep 10; done;
echo "All done!";
'
healthcheck:
test: ["CMD-SHELL", "[ -f config/certs/es01/es01.crt ]"]
interval: 1s
timeout: 5s
retries: 120
es01:
depends_on:
setup:
condition: service_healthy
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
labels:
co.elastic.logs/module: elasticsearch
volumes:
- certs:/usr/share/elasticsearch/config/certs
- esdata01:/usr/share/elasticsearch/data
ports:
- ${ES_PORT}:9200
environment:
- node.name=es01
- cluster.name=${CLUSTER_NAME}
- discovery.type=single-node
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
- bootstrap.memory_lock=true
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=true
- xpack.security.http.ssl.key=certs/es01/es01.key
- xpack.security.http.ssl.certificate=certs/es01/es01.crt
- xpack.security.http.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.key=certs/es01/es01.key
- xpack.security.transport.ssl.certificate=certs/es01/es01.crt
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.license.self_generated.type=${LICENSE}
mem_limit: ${ES_MEM_LIMIT}
ulimits:
memlock:
soft: -1
hard: -1
healthcheck:
test:
[
"CMD-SHELL",
"curl -s --cacert config/certs/ca/ca.crt https://localhost:9200 | grep -q 'missing authentication credentials'",
]
interval: 10s
timeout: 10s
retries: 120
kibana:
depends_on:
es01:
condition: service_healthy
image: docker.elastic.co/kibana/kibana:${STACK_VERSION}
labels:
co.elastic.logs/module: kibana
volumes:
- certs:/usr/share/kibana/config/certs
- kibanadata:/usr/share/kibana/data
ports:
- ${KIBANA_PORT}:5601
environment:
- SERVERNAME=kibana
- ELASTICSEARCH_HOSTS=https://es01:9200
- ELASTICSEARCH_USERNAME=kibana_system
- ELASTICSEARCH_PASSWORD=${KIBANA_PASSWORD}
- ELASTICSEARCH_SSL_CERTIFICATEAUTHORITIES=config/certs/ca/ca.crt
- XPACK_SECURITY_ENCRYPTIONKEY=${ENCRYPTION_KEY}
- XPACK_ENCRYPTEDSAVEDOBJECTS_ENCRYPTIONKEY=${ENCRYPTION_KEY}
- XPACK_REPORTING_ENCRYPTIONKEY=${ENCRYPTION_KEY}
mem_limit: ${KB_MEM_LIMIT}
healthcheck:
test:
[
"CMD-SHELL",
"curl -s -I http://localhost:5601 | grep -q 'HTTP/1.1 302 Found'",
]
interval: 10s
timeout: 10s
retries: 120
Here the .env file in the same directory:
# Project namespace (defaults to the current folder name if not set)
#COMPOSE_PROJECT_NAME=myproject
# Password for the 'elastic' user (at least 6 characters)
ELASTIC_PASSWORD=changeme
# Password for the 'kibana_system' user (at least 6 characters)
KIBANA_PASSWORD=changeme
# Version of Elastic products
STACK_VERSION=8.7.1
# Set the cluster name
CLUSTER_NAME=docker-cluster
# Set to 'basic' or 'trial' to automatically start the 30-day trial
LICENSE=basic
#LICENSE=trial
# Port to expose Elasticsearch HTTP API to the host
ES_PORT=9200
# Port to expose Kibana to the host
KIBANA_PORT=5601
# Increase or decrease based on the available host memory (in bytes)
ES_MEM_LIMIT=1073741824
KB_MEM_LIMIT=1073741824
LS_MEM_LIMIT=1073741824
# SAMPLE Predefined Key only to be used in POC environments
ENCRYPTION_KEY=c34d38b3a14956121ff2170e5030b471551370178f43e5626eec58b04a30fae2
As shown in the above, password is changeme for Kibana.
To setup run the docker compose command:
docker compose up
This will create three volumes as follows:
If you want to access Elasticsearch API, you need to first copy certifcate to temp directory. To get the file first find the name of the Elasticsearch container.

In the above diagram ❷ shows the container name. Copy the cert file to the temp directory:
docker cp elastic_es01_1:/usr/share/elasticsearch/config/certs/ca/ca.crt /tmp/.
To test run the following command in the same host where docker instances are running:
curl --cacert /tmp/ca.crt -u elastic:changeme https://localhost:9200
It should give you the result:
{
"name" : "es01",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "p2gzCZh9TYeW8WBGJOaNXw",
"version" : {
"number" : "8.7.1",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "f229ed3f893a515d590d0f39b05f68913e2d9b53",
"build_date" : "2023-04-27T04:33:42.127815583Z",
"build_snapshot" : false,
"lucene_version" : "9.5.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
To access the Kibana, use the follow url http://<host ip>:5601 from anywhere.
To check the health of the cluster:
curl --cacert ca.crt -u elastic:changeme https://localhost:9200/_cluster/health
Or in Kibana
GET _cluster/health
To enable trial version:
POST /_license/start_trial?acknowledge=true
CURD
You can create index as follows:
PUT fruits
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
To get the details of the fruits index:
GET fruits/_settings
Add documents:
POST fruits/_doc
{
"name":"Mango",
"qty": 2
}
Add
The POST will add the _id automatically.
If you use PUT, you need to provide the document id as follows:
PUT fruits/_doc/1
{
"name":"Mango",
"qty": 2
}
Warning: The
_docendpoing will overwrite the existing document.
Get the added document:
GET fruits/_search
output
{
"took": 444,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "fruits",
"_id": "i7dcWosBlpsdZwgSyFwT",
"_score": 1,
"_source": {
"name": "Mango",
"qty": 2
}
},
{
"_index": "fruits",
"_id": "1",
"_score": 1,
"_source": {
"name": "Mango",
"qty": 2
}
}
]
}
}
To get the document by id
GET fruits/_doc/1
To avoid rewrite existing document use create endpoint.
For example above following PUT will generate error:
PUT fruits/_create/1
{
"name":"Mango",
"qty": 3
}
This will generate 409 error message.
Update
To update only the quantity of the above document:
POST fruits/_update/1
{
"doc":{
"qty": 3
}
}
Here, used the _update endpoin.
Delete
How to delete a document:
DELETE fruits/_doc/1
Search
When search query is sent, Elasticsearch retrieves relevant documents.
| Index |  |
|---|---|
| True & False Possitves |  |
| True & False Negatives |  |
| Precision |  |
| Recall |  |
Precision: What portion of the retrieved data is actually relevant to the search query.
Recall: What portion of relevant data is being returned as search results.
Precision and Recall are inversely related.
More relevant document are higher the score. The score is a value that represents how relevant a document is to that specific query as well as Elasticsearch compute the score for each document for that hit. To score, Elasticsearch uses TF/IDF.
Mapping
Index mapping is a process of defining how a document must be mapped in the search engine. Along with the data type, mapping allows you to set the field characteristics such as searchable, returnable, sortable, how to store, date format, whether the strings must be treated as full text fields, and so on.
Dynamic Mapping
When you create a document for the first time, Elasticsearch creates an index as well as the mapping schema based on the document’s field values. This type of mapping is called dynamic mapping.
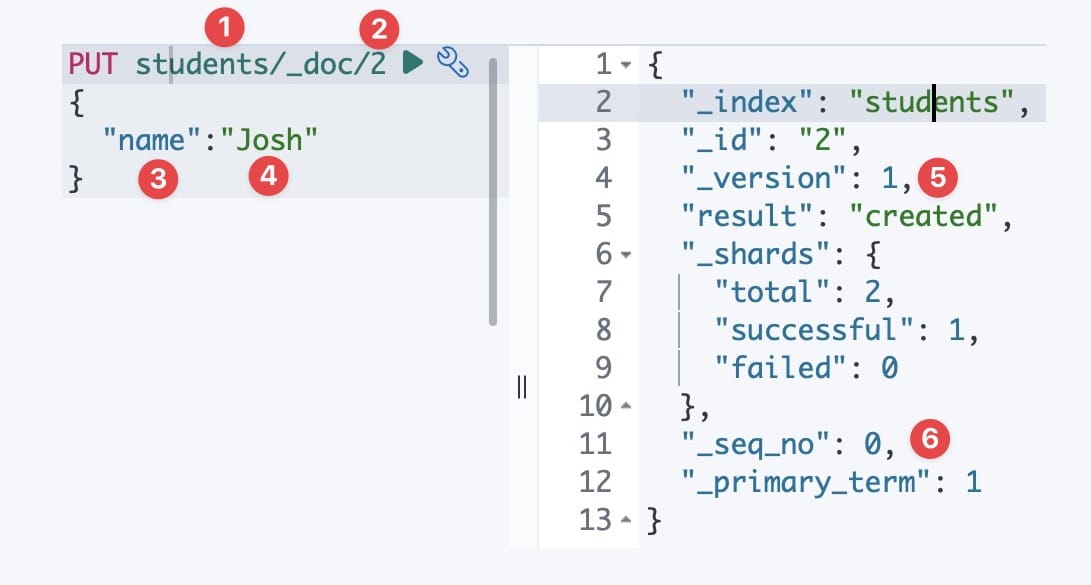
Get mapping details of specific property:
GET students/_mapping/field/name.first.keyword
Get without source
GET students/_doc/1?_source=false
To get multiple documents as the same time
GET students/_mget
{
"ids":[1,2,3]
}
if you want to avoid missing one
GET students/_search
{
"query": {
"ids": {
"values": [1,2,3]
}
}
}
for the doc
PUT students/_doc/2
{
"name":"Josh",
"subjects": ["Maths","English"]
}
Query
GET students/_source/2
output
{
"name": "Josh",
"subjects": [
"Maths",
"English"
]
}
Only for the name
GET students/_source/2/?_source_includes=name
output
{
"name": "Josh"
}
For the document
PUT students/_doc/2
{
"name":{
"first":"Josh",
"last": "JoshLastName"
},
"subjects": ["Maths","English"]
}
Get only the nested last name of the source
GET students/_source/2/?_source_includes=name.last
To only update the nested last name:
POST students/_update/2
{
"doc":{
"name":{
"last": "Brown"
}
}
}
Explicit Mapping
You can define explicit mapping at an index level3.
- String: You can save a string field as of type,
textorkeyword.- The
texttype is used to index full-text values, such as the description of a product. These fields are analyzed by an analyzer to convert the string into a list of individual terms before being indexed. - The
keywordfield type is used for structured content such as IDs, email addresses, hostnames, status codes, or zip codes, and the entire content of the field is indexed and searched as one unit.
- The
- Numeric: You can use the numeric field types to define fields that are holding numeric data. The various numeric field types supported includes
- long,
- integer,
- short,
- byte,
- double,
- float.
- Date: A field to hold a date type can be defined using the
datetype. This field can hold formatted date strings. - Boolean: This field accepts the JSON values
trueandfalse. But, can also accept strings that are interpreted as eithertrueorfalse. - Object: You can use this field type for fields consisting of JSON objects, which can contain subfields.
- Arrays: This is a
nestedfield type can be used for arrays of objects to be indexed in a way that they can be queried independently of each other.
Characteristics
You can group the field types under one or more of the following characteristics:
- Searchable: A searchable field is one which is indexed and the document containing the field can be searched and retrieved by the value of the field. The behavior of a searchable field varies based on whether the field is defined as
analyzedornon-analyzed. - Returnable: A returnable field is one which is stored and the field value can be returned as part of the search response.
- Sortable: A sortable field is one, based on which the search results can be sorted in a particular order, either
descorasc. The search results can be ordered by one or more sortable fields.
Common Data types
None text-analysis process are ideal candidates for the keyword data type. Elasticsearch supports dates by providing a date type as well as additional options to format dates. Define a format of your own choosing, say you want to set open_day in UK format (“dd-MM-yyyy”)
"open_day":{
"type": "date",
"format":"dd-MM-yyyy"
}
or multiple formats as:
"open_day":{
"type": "date",
"format":"dd-MM-yyyy||dd/MM/yyyy||MM-dd-yyyy||MM/dd/yyyy"
}
if you create mapping as follows:
PUT universities
{
"mappings" :{
"properties" :{
"name":{
"type":"text"
},
"telephone_number":{
"type": "keyword"
},
"contact_email":{
"type": "keyword"
},
"open_day":{
"type": "date",
"format":"dd-MM-yyyy||dd/MM/yyyy||MM-dd-yyyy||MM/dd/yyyy"
}
}
}
}
you can insert the following documents with different date formats:
# dd-MM-yyyy
PUT universities/_doc/1
{
"name":"University of A",
"telephone_number":"01865270000",
"contact_email":"info@a.edu.au",
"open_day":"02-09-2022"
}
# dd/MM/yyyy
PUT universities/_doc/2
{
"name":"University of B",
"telephone_number":"01865280000",
"contact_email":"info@b.edu.au",
"open_day":"02/09/2022"
}
# MM-dd-yyyy
PUT universities/_doc/3
{
"name":"University of C",
"telephone_number":"01865290000",
"contact_email":"info@c.edu.au",
"open_day":"09-02-2022"
}
# MM/dd/yyyy
PUT universities/_doc/4
{
"name":"University of D",
"telephone_number":"01865210000",
"contact_email":"info@d.edu.au",
"open_day":"09/02/2022"
}
list the document by id
# get document by the id of the document
GET universities/_doc/2
# get field type
GET universities/_mapping/field/name
The following table describes he default behavior of the various field types:
| Field Type | Searchable | Analyzed | Returnable | Sortable |
|---|---|---|---|---|
| Text | Yes | Yes | No | No |
| Keyword | Yes | No | No | Yes |
| Numeric | Yes | No | No | Yes |
| Boolean | Yes | No | No | Yes |
| Date | Yes | No | No | Yes |
Structured data, such as codes, bank accounts, or phone numbers, are represented by the keyword data type.Elasticsearch provides five integer types to handle integer numbers: byte, short, integer, long, and unsigned_long.
# create a index mappings
PUT employees
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"level": {
"type": "byte"
},
"age": {
"type": "short"
},
"employee_id": {
"type": "integer"
},
"salary": {
"type": "float"
},
"pyg":{
"type": "boolean"
}
}
}
}
# add a document to the created index
PUT employees/_doc/1
{
"name":"John Smith",
"employee_id":1234567,
"level":4,
"age":21,
"salary": 156000.56,
"pyg": true
}
# list the contents of the index
GET employees/_search
Declaring Multi-Types
Let’s look at the example schema definition that creates our single field title with multiple data types (text, keyword, and completion):
PUT movies
{
"mappings": {
"properties": {
"title":{
"type": "text",
"fields": {
"kw":{ "type":"keyword" },
"comp":{ "type":"completion" }
}
}
}
}
}
The
completionsuggester provides auto-complete/search-as-you-type functionality. This is a navigational feature to guide users to relevant results as they are typing, improving search precision.
output schema is
{
"movies": {
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"comp": {
"type": "completion",
"analyzer": "simple",
"preserve_separators": true,
"preserve_position_increments": true,
"max_input_length": 50
},
"kw": {
"type": "keyword"
}
}
}
}
}
}
}
Geo Point Data Type
Location data is expressed as a geo_point data type, which represents longitude and latitude values on a map. You can use this to pinpoint an address for a restaurant, a school, a golf course, and others.
The code below creates the schema definition of a schools index with two fields: name and an address. Note that the address field is defined as a geo_point data type:
PUT schools
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"address":{
"type": "geo_point"
}
}
}
}
field is expected to be set with a pair of latitude and longitude data:
PUT schools/_doc/1
{
"name":"School of Coding",
"address":"51.5145, 0.1595"
}
you can provide the coordinates as an array or in GeoJSON format or Well-Known-Text (WKT) formats:
# Latitude and longitude as an object:
PUT schools/_doc/2
{
"name":"School of Science",
"address":{
"lat":"51.5145",
"lon":"0.1595"
}
}
# Latitude and longitude as an Array
# (note the order of values - they are lon and lat):
PUT schools/_doc/3
{
"name":"School of Arts",
"address":[0.1595, 51.5145]
}
Elasticsearch provides the Object data type to hold such hierarchical data
PUT employees
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "object",
"properties": {
"house_number": {
"type": "text"
},
"street": {
"type": "text"
},
"city": {
"type": "text"
},
"postcode": {
"type": "text"
}
}
}
}
}
}
However, note that by default every object in Elasticsearch is an
objecttype, so this declaration is redundant.
Document samples:
PUT employees/_doc/1
{
"name":"John Smith",
"address":{
"house_number":"321",
"street":"Beta Street",
"city":"Sydney",
"postcode":"2000"
}
}
PUT employees/_doc/2
{
"name":"Grace Smith",
"address":{
"house_number":"123A",
"street":"Alpha Street",
"city":"Sydney",
"postcode":"2000"
}
}
PUT employees/_doc/3
{
"name":"Simon Stud",
"address":{
"house_number":"82",
"street":"Karma way",
"city":"Hornsby",
"postcode":"2077"
}
}
if you want to return all the employees live in Sydney, notice the propertiy is address.city:
GET employees/_search
{
"query": {
"match": {
"address.city": "Sydney"
}
}
}
Joins
Every document that gets indexed is independent and maintains no relationship with any others in that index. Elasticsearch de-normalizes the data to achieve speed and gain performance during indexing and search operations. Elasticsearch provides a join data type to consider parent-child relationships should you need them.
You need to create an index mentioning the teacher-student relationship. The hard part is understanding this schema definition, so let’s take it a bit slow here.
PUT teachers
{
"mappings": {
"properties": {
"relationship":{
"type": "join",
"relations":{
"teacher":"student"
}
}
}
}
}
As we have the schema definition for teacher-student relationship indexed, let’s create a teacher:
PUT teachers/_doc/1
{
"name":"Ruth Randall",
"relationship":{
"name":"teacher"
}
}
Now that the teacher is ready, let’s attach some students.
Let’s index two students, both attached to teacher Ruth. Make sure that the relationship declared via name is student. You also need to provide the routing with a key (we are using ruth as the key). The routing key for all students must be same key:
PUT teachers/_doc/2?routing=ruth
{
"name":"John Smith",
"relationship":{
"name":"student",
"parent":1
}
}
PUT teachers/_doc/3?routing=ruth
{
"name":"Angela Krishnan",
"relationship":{
"name":"student",
"parent":1
}
}
The relationship object should have the value set as student (remember the parent-child portion of the relations attribute in the schema?) and the parent should be assigned a document identifier of the associated teacher (ID 1), Ruth in our example.
#Search
GET teachers/_search
{
"query": {
"parent_id":{
"type":"student",
"id":1
}
}
}
This will return all the students of teacher Ruth.
Bulk
The _bulk API consists of a specific syntax with a POST method invoking the API call. Let’s first see the query and check the details.
When you run the following query in Kibana->Dev Tools:
POST _bulk
{"index":{"_index":"movies","_id":"1"}}
{"title": "Top Gun Maverick","actors": "Tom Cruise"}
{"index":{"_index":"movies","_id":"2"}}
{"title": "Mission Impossible","actors": "Tom Cruise"}
output is
{
"took" : 132,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "movies",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "movies",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
}
]
}
The request body consists of two lines for every document that needs to be stored:
- The first line indicates the action and the metadata. In this case we are indexing a document (hence “index”) with ID 1 into an index called
movies. - The second line is the document itself—NDJSON (short for “new line delimited JSON”) representation of the data. The document is formatted in JSON and added in the new line to the request.
NOTE: We can also perform other actions, such as
create,update, anddelete.{"delete":{"_index":"movies","_id":"1"}}you wish to delete the document with ID 1, above is the first line will look like. You don’t need a second line to delte.
Let’s index a bunch of Tom Cruise’s movies using the _bulk API, but this time we won’t supply IDs for the movies:
POST movies/_bulk
{"index":{}}
{"title": "Mission Impossible","release_date": "1996-07-05"}
{"index":{}}
{"title": "Mission Impossible II","release_date": "2000-05-24"}
{"index":{}}
{"title": "Mission Impossible III","release_date": "2006-05-03"}
{"index":{}}
{"title": "Mission Impossible - Ghost Protocol","release_date": "2011-12-26"}
Two things to note from the previous query:
- The request has an index name (
movies) mentioned in the URL rather than from the first line - No
IDis provided for the document
Bulk Create
Let’s index some documents and try out create action.
NOTE: The
createaction allows an additional check when indexing the document; that is, the action doesn’t replace an existing document.
The following code snippet creates new tv shows using the create action and bulk API:
POST _bulk
{"create":{"_index":"tv_shows","_id":"1"}}
{"title": "Man vs Bee","actors":"Rowan Atkinson","release_date": "2022-06-24"}
{"create":{"_index":"tv_shows","_id":"2"}}
{"title": "Killing Eve","actors":["Jodie Comer","Sandra Oh"],"release_date": "2018-04-08"}
{"create":{"_index":"tv_shows","_id":"3"}}
{"title": "Peaky Blinders","actors":"Cillian Murphy","release_date": "2013-09-12"}
the output is
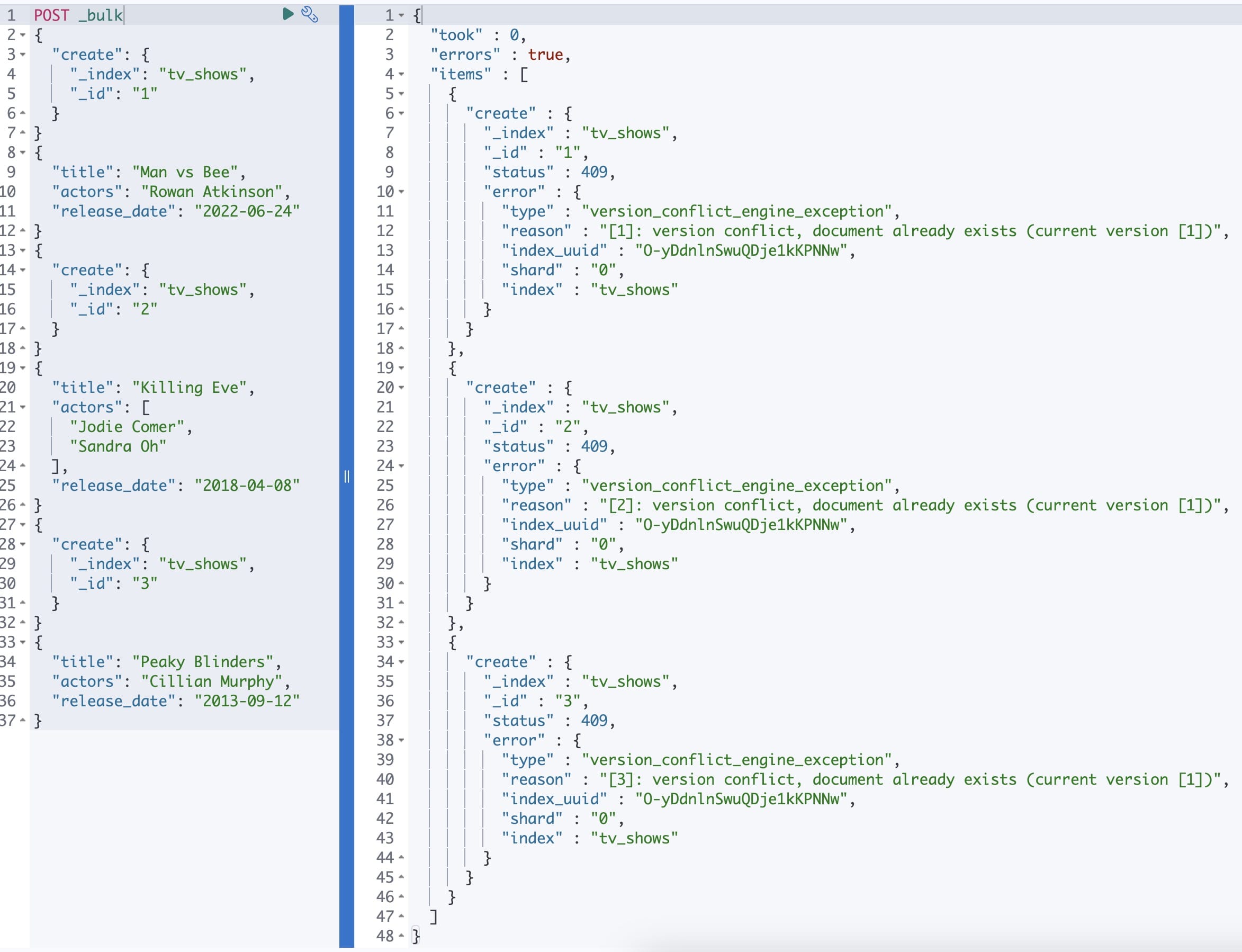
Bulk command to insert data from ndjson file
curl --cacert ca.crt -u elastic:changeme https://localhost:9200/hockey/_bulk?pretty -H 'Content-Type: application/json' -k --data-binary @hockey.json
The sample ndjson is
{"index":{"_id":1}}
{"first":"johnny","last":"gaudreau","goals":[9,27,1],"assists":[17,46,0],"gp":[26,82,1],"born":"1993/08/13"}
{"index":{"_id":2}}
{"first":"sean","last":"monohan","goals":[7,54,26],"assists":[11,26,13],"gp":[26,82,82],"born":"1994/10/12"}
{"index":{"_id":3}}
{"first":"jiri","last":"hudler","goals":[5,34,36],"assists":[11,62,42],"gp":[24,80,79],"born":"1984/01/04"}
{"index":{"_id":4}}
{"first":"micheal","last":"frolik","goals":[4,6,15],"assists":[8,23,15],"gp":[26,82,82],"born":"1988/02/17"}
{"index":{"_id":5}}
{"first":"sam","last":"bennett","goals":[5,0,0],"assists":[8,1,0],"gp":[26,1,0],"born":"1996/06/20"}
{"index":{"_id":6}}
{"first":"dennis","last":"wideman","goals":[0,26,15],"assists":[11,30,24],"gp":[26,81,82],"born":"1983/03/20"}
{"index":{"_id":7}}
{"first":"david","last":"jones","goals":[7,19,5],"assists":[3,17,4],"gp":[26,45,34],"born":"1984/08/10"}
{"index":{"_id":8}}
{"first":"tj","last":"brodie","goals":[2,14,7],"assists":[8,42,30],"gp":[26,82,82],"born":"1990/06/07"}
{"index":{"_id":39}}
{"first":"mark","last":"giordano","goals":[6,30,15],"assists":[3,30,24],"gp":[26,60,63],"born":"1983/10/03"}
{"index":{"_id":10}}
{"first":"mikael","last":"backlund","goals":[3,15,13],"assists":[6,24,18],"gp":[26,82,82],"born":"1989/03/17"}
{"index":{"_id":11}}
{"first":"joe","last":"colborne","goals":[3,18,13],"assists":[6,20,24],"gp":[26,67,82],"born":"1990/01/30"}
NOTE: All the lines should be terminated by new line character \n.
Text Analysis
The analyzer is a software module tasked with two functions4:
- tokenization: the process of splitting sentences into individual words
- normalization: where the tokens (words) are massaged, transformed, modified, and enriched in the form of stemming, synonyms, stop words, and other features
The
textfields are thoroughly analyzed and stored in inverted indexes for advanced query matching.
Stemming is an operation where words are reduced (stemmed) to their root words (for example, “author” is the root word for “authors”, “authoring”, and “authored”).
Normalization also finds synonyms and adding them to the inverted index. For example, “author” may have additional synonyms, such as “wordsmith”, “novelist”, “writer”, and so on.
The Stop words are such as English grammar articles they are irrelevant to find the relevant documents.
Appendix
Download schema
wget http://media.sundog-soft.com/es8/shakes-mapping.json
Create Mappings
curl --cacert /tmp/ca.crt -u elastic:changeme -H "Content-Type: application/json" -XPUT https://localhost:9200/shakespeare -k --data-binary @shakes-mapping.json
Download data
wget http://media.sundog-soft.com/es8/shakespeare_8.0.json
Insert bulk of data
curl --cacert /tmp/ca.crt -u elastic:changeme -H "Content-Type: application/json" -XPUT 'https://localhost:9200/shakespeare/_bulk' -k --data-binary @shakespeare_8.0.json
Using Kibana Visualizer, you can directly import the News Headlines5 dataset as explained in the post6.
To find the cluster health
GET _nodes/stats
My Queries
GET news_headlines/_search
{
"query": {
"match": {
"headline": {
"query": "Khloe Kardashian Kendall Jenner",
"minimum_should_match": 3
}
}
}
}
GET news_headlines/_search
{
"aggs": {
"by_category": {
"terms": {
"field": "category",
"size": 10
}
}
}
}
GET news_headlines/_search
{
"query": {
"match_phrase": {
"headline": "Shape of you"
}
}
}
GET news_headlines/_search
{
"query": {
"multi_match": {
"query": "Michelle Obama",
"fields": [
"headline",
"short_description",
"authors"]
}
}
}
GET news_headlines/_search
{
"query": {
"multi_match": {
"query": "party planning",
"fields": [
"headline^2",
"short_description",
"authors"],
"type": "phrase"
}
}
}
GET news_headlines/_search
{
"query": {
"match_phrase": {
"headline": "Michelle Obama"
}
},
"aggs": {
"category_mentions": {
"terms": {
"field": "category",
"size": 100
}
}
}
}
GET news_headlines/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"headline": "Michelle Obama"
}
},
{
"match": {
"category": "POLITICS"
}
}
]
}
}
}
GET news_headlines/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"headline": "Michelle Obama"
}
}],
"must_not": [
{
"match": {
"category": "POLITICS"
}
}
]
}
}
}
GET news_headlines/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"headline": "Michelle Obama"
}
}],
"should": [
{
"match": {
"category": "POLITICS"
}
}
]
}
}
}
GET news_headlines/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"headline": "Michelle Obama"
}
}
],
"filter": {
"range": {
"date": {
"gte": "2014-03-25",
"lte": "2015-03-25"
}
}
}
}
}
}
Part-4
GET ecommerce_data/_search
{
"size": 0,
"query": {
"match": {
"Country": "Germany"
}
},
"aggs": {
"cardinality of UnitPrice": {
"avg": {
"field": "UnitPrice"
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"cardinality of customers": {
"cardinality": {
"field": "CustomerID"
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"stats unit price": {
"stats": {
"field": "UnitPrice"
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"transactions by 8 hours": {
"date_histogram": {
"field": "InvoiceDate",
"fixed_interval": "8h"
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"transactions by month": {
"date_histogram": {
"field": "InvoiceDate",
"calendar_interval": "1M"
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"transactions by month": {
"date_histogram": {
"field": "InvoiceDate",
"calendar_interval": "1M",
"order": {
"_key": "desc"
}
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"txn for price intervals": {
"histogram": {
"field": "UnitPrice",
"interval": 10
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"txn for price intervals": {
"histogram": {
"field": "UnitPrice",
"interval": 10,
"order": {
"_key": "desc"
}
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"txn for custom price ranges": {
"range": {
"field": "UnitPrice",
"ranges": [
{
"to": 50
},
{
"from": 50,
"to": 200
},
{
"from": 200
}
]
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"top 5 customers": {
"terms": {
"field": "CustomerID",
"size": 5
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"top 5 customers with lowest # txns": {
"terms": {
"field": "CustomerID",
"size": 5,
"order": {
"_count": "asc"
}
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"transactions by month": {
"date_histogram": {
"field": "InvoiceDate",
"calendar_interval": "day"
},
"aggs": {
"daily_revenue": {
"sum": {
"script": {
"source": "doc['UnitPrice'].value * doc['Quantity'].value"
}
}
}
}
}
}
}
GET ecommerce_data/_search
{
"size": 0,
"aggs": {
"transactions by month": {
"date_histogram": {
"field": "InvoiceDate",
"calendar_interval": "day",
"order": {
"daily_revenue": "desc"
}
},
"aggs": {
"daily_revenue": {
"sum": {
"script": {
"source": "doc['UnitPrice'].value * doc['Quantity'].value"
}
}
},
"number of unique customers per day": {
"cardinality": {
"field": "CustomerID"
}
}
}
}
}
}
from elasticsearch import Elasticsearch
# Password for the 'elastic' user generated by Elasticsearch
ELASTIC_PASSWORD = "changeme"
# Create the client instance
client = Elasticsearch(
"https://localhost:9200",
ca_certs="ca.crt",
basic_auth=("elastic", ELASTIC_PASSWORD)
)
client.info()
REFERENSES: