PySpark Data Frame to Pie Chart
Table of Contents
I am sharing a Jupyter notebook.
This shows:
- Access to PostgreSQL database connection
- How to draw Pie Chart
- SQL shows common table expression
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Postgres Connection") \
.config("spark.jars", # add the PostgresSQL jdbc driver jar
"/home/jovyan/work/extlibs/postgresql-9.4.1207.jar").getOrCreate()
db_name = 'dvdrental'
sql = """
WITH first_orders AS (
SELECT * FROM (
SELECT p.payment_id
, p.customer_id
, p.payment_date
, p.rental_id
, p.amount
, row_number() over (PARTITION BY p.customer_id ORDER BY p.payment_date) as rn
FROM payment p) t WHERE t.rn =1
),
summary AS (SELECT *
FROM first_orders fo
JOIN rental r ON r.rental_id = fo.rental_id
JOIN inventory i ON i.inventory_id = r.inventory_id
JOIN film f ON f.film_id = i.film_id
)
SELECT s.rating, SUM(s.amount)
FROM summary s GROUP BY s.rating
"""
db_props = {"user":"postgres","password":"ojitha","driver":"org.postgresql.Driver"}
df1 = spark.read.jdbc(url="jdbc:postgresql://Mastering-postgres:5432/%s" % db_name,
table='(%s) as foo' % sql, # SQL query to create dataframe
properties= db_props)
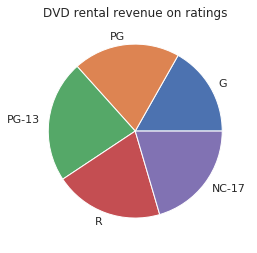
df1.show(6)
+------+--------------------+
|rating| sum|
+------+--------------------+
| G|407.0800000000000...|
| PG|480.8500000000000...|
| PG-13|549.6200000000000...|
| R|489.7400000000000...|
| NC-17|495.7200000000000...|
+------+--------------------+
#define data
df = df1.toPandas()
import matplotlib.pyplot as plt
fig = plt.pie(df['sum'], labels=df['rating'])
plt.title('DVD rental revenue on ratings')
plt.show()
spark.stop()